CLH队列锁原理解析
CLH锁
CLH锁,全称:Craig, Landin, and Hagersten (CLH) locks。(CLH是三位大佬名字的首字母) CLH锁,一种基于FIFO队列的自旋锁,提供先来先服务的公平性。确保无饥饿性。 饥饿性:一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行的状态。
核心思想
CLH锁也是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程仅仅在本地变量上自旋,它不断轮询前驱的状态,假设发现前驱释放了锁就结束自旋。
原理
- 首先有个
节点CLHNode,这个节点CLHNode记录锁的状态,true为锁定状态,false为释放状态; - 然后有一个
尾节点指针tailNode,这个尾节点指针tailNode始终指向队列的最后一个结点,可以理解为实时的节点状态信息;此外这个尾节点指针tailNode是原子引用类型,避免了多线程并发操作的线程安全性问题; - 此外每个线程在自己的本地变量中都有一个
当前节点curNode和前继节点predNode;当前节点curNode记录锁为锁定状态(此时的锁定状态并没有生效),同时被下一个线程的前继节点predNode指向着;每个线程在前继节点predNode自旋,也就是自旋不停的查看上个线程中的节点信息的锁的状态,当锁为释放状态;则停止自旋,当前节点curNode锁的状态生效。
CLH锁的队列是隐式的,概念上的队列;并没有实际的指针串联
代码实现
CLHQueueLock.java
public class CLHQueueLock {
/**
* CLH锁节点
*/
private class CLHNode {
/**
* 锁状态:true表示锁定状态、false表示释放状态
* 为了保证locked状态是线程间可见的,因此用volatile关键字修饰
*/
volatile boolean locked = false;
}
/**
* 当前节点
* 每个线程拥有自己的副本用于记录自己线程中持有的CLH节点状态信息
*/
private final ThreadLocal<CLHNode> curNode;
/**
* 前继节点(指向前一个线程中持有的CLH节点信息)
* 每个线程拥有自己的副本用于记录自己线程中持有的CLH节点状态信息
*/
private final ThreadLocal<CLHNode> predNode;
/**
* 最后一个队列种CLH节点的状态信息
* 【注意】这里用了java的原子系列之AtomicReference,能保证原子更新
*/
private final AtomicReference<CLHNode> tailNode;
/**
* 初始化几个节点信息
*/
CLHQueueLock() {
// 初始化当前线程(即实例化锁的线程)的CLH节点,锁状态为false;这个方法会为子线程创建副本
curNode = ThreadLocal.withInitial(CLHNode::new);
// 初始化前继节点,注意此时前,存储的是null
predNode = new ThreadLocal<>();
// 初始化最后一个队列种CLH节点的状态信息
tailNode = new AtomicReference<>(curNode.get());
}
/**
* 获取锁
*/
void lock() {
// 取出当前线程ThreadLocal存储的当前节点
// 子线程都是获取父线程初始化的值,locked状态为false。
CLHNode currNode = curNode.get();
// 此时把lock状态置为true,表示一个有效状态,
// 表示当前线程的锁为锁定状态,具体是否生效也需要看下面逻辑
currNode.locked = true;
// 记录实时的节点信息(先get再set;先get就是获取了上个节点信息,再set就是把当前线程更新过的进行设值)
// 【注意】在多线程并发情况下,这里通过AtomicReference类能防止并发问题
// 【注意】这个会导致锁不能重入(不着重说明了)
CLHNode preNode = tailNode.getAndSet(currNode);
// 将刚获取的尾结点(前一线程的当前节点)付给当前线程的前继节点
// 这里必须设值,不然下个线程进来也有可能不进行自旋(两个线程同时进入不设值则获取的前继节点状态都是false)
//前继节点需要等待解锁进行改变
predNode.set(preNode);
int spinCount = 0;
//开始自旋,自旋前继节点(等待前继节点释放锁);自旋结束后则表明当前线程的CLH节点状态生效
while (predNode.get().locked) {
spinCount++;
}
System.out.println("线程" + Thread.currentThread().getName() + "自旋" + spinCount + "次后获取了锁");
}
/**
* 释放锁
*/
void unLock() {
// 获取当前线程的当前节点
CLHNode node = curNode.get();
// 进行解锁操作
node.locked = false;
System.out.println("线程" + Thread.currentThread().getName() + "释放了锁!!!");
predNode.remove();
// 小伙伴们可以思考下,下面两句代码的作用是什么??
// CLHNode newCurNode = new CLHNode();
// curNode.set(newCurNode);
// 【优化】能提高GC效率和节省内存空间,请思考:这是为什么?
// curNode.set(predNode.get());
}
}
CLHQueueLockTest.java
public class CLHQueueLockTest extends Thread {
private static int count = 0;
private static CLHQueueLock lock = new CLHQueueLock();
@Override
public void run() {
lock.lock();
try {
for (int i = 0; i < 1000; i++) {
count++;
}
} finally {
lock.unLock();
}
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[100];
for (int i = 0; i < threads.length; i++) {
CLHQueueLockTest clhQueueLockTest = new CLHQueueLockTest();
threads[i] = clhQueueLockTest;
threads[i].start();
}
for (Thread thread : threads) {
thread.join();
}
System.out.println("count=" + count);
}
}
流程图说明
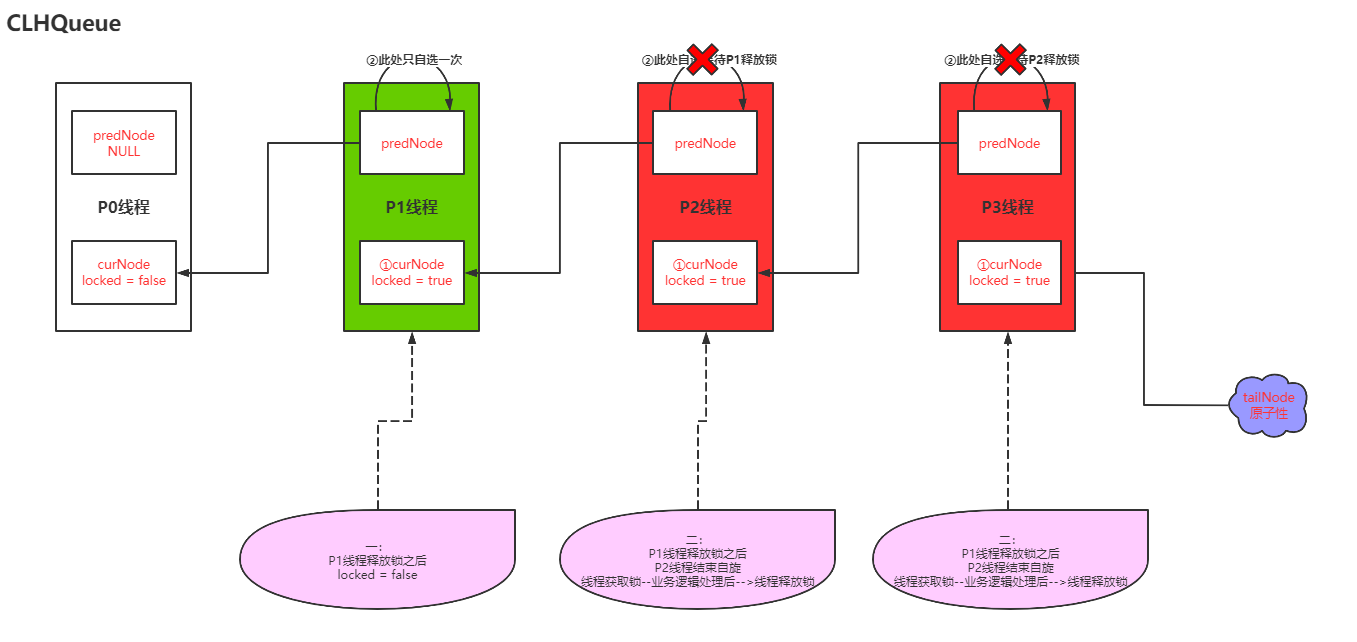
假设有三个并发线程同时启动执行lock操作,假如三个线程的实际执行顺序为:P1 –> P2 –> P3;其中存在一个初始化所得线程,在这里我们设置为P0
-
第一步初始化
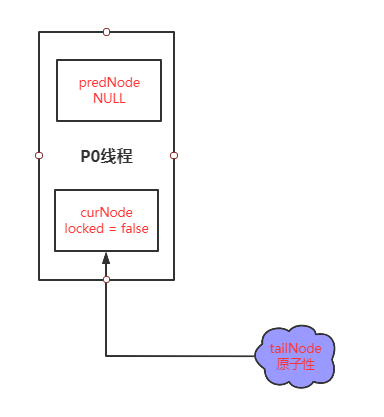
-
第二步P1线程去获取锁,获取成功
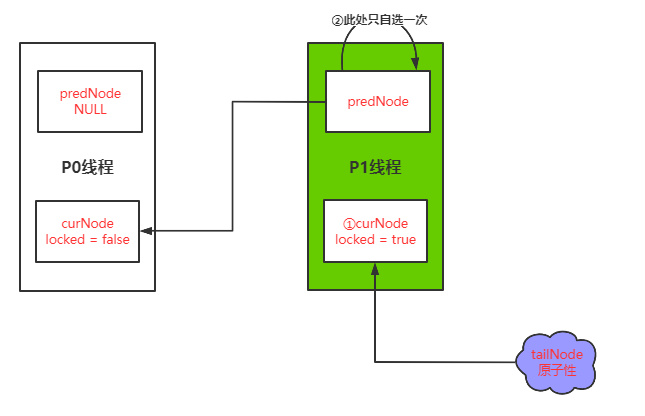
-
第三步P2线程去获取锁,P1锁定,P2自旋
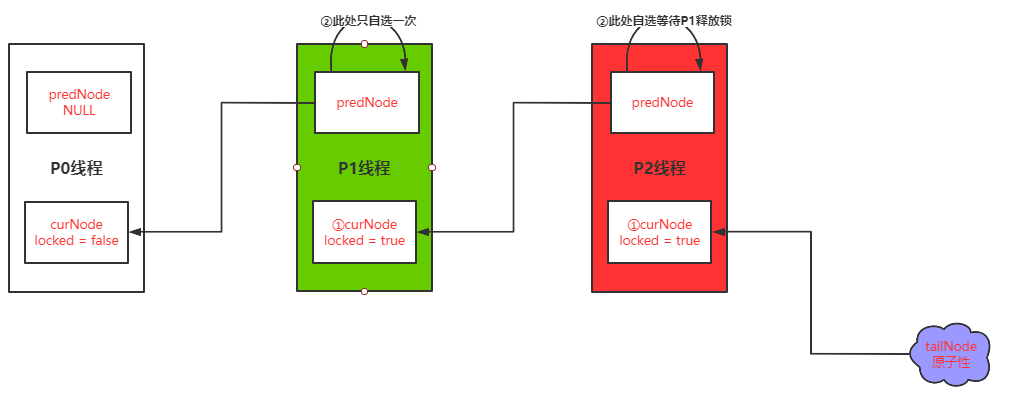
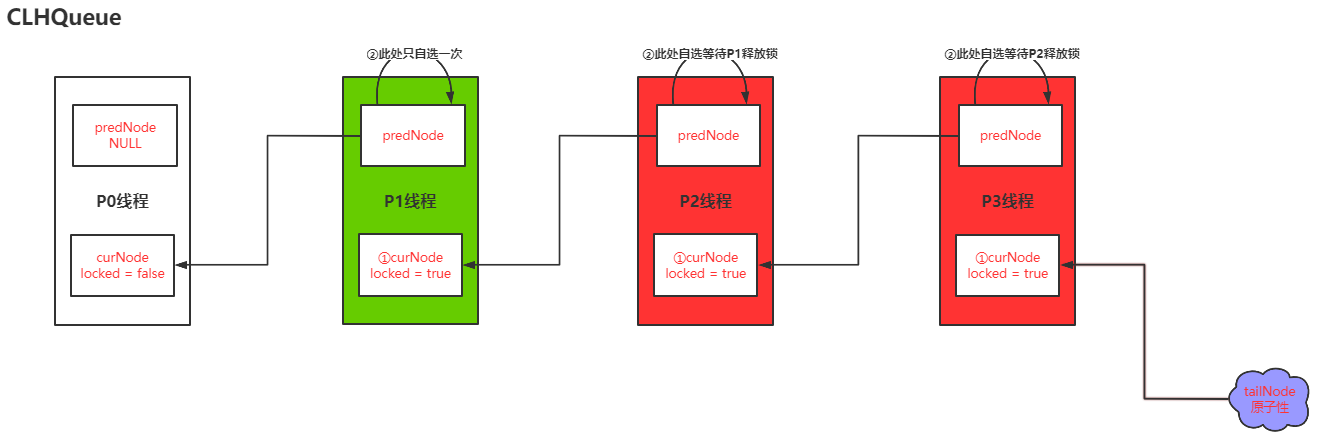
-
第四步P3线程去获取锁,P2锁定,P3自旋(这个就成了链表关系,P2自旋等待P1释放锁,P3自旋等待P2释放锁;此时形成的队列就很明显了)
加锁得过程很明确之后,释放锁得过程也就很清楚明了了。
至此对于CLH队列锁了解的可能就差不多了,下面就需要考虑下是否重入,同一个线程是否可以重复的进行“加锁-->解锁”过程
优缺点
优点 CLH队列锁的优点是空间复杂度低(如果有n个线程,L个锁,每个线程每次只获取一个锁,那么需要的存储空间是O(L+n),n个线程有n个myNode,L个锁有L个tail) 缺点 在NUMA系统结构下性能很差,在这种系统结构下,每个线程有自己的内存,如果前趋结点的内存位置比较远,自旋判断前趋结点的locked域,性能将大打折扣,但是在SMP系统结构下该法还是非常有效的。
一种解决NUMA系统结构的思路是MCS队列锁。
SMP/NUMA 系统结构
SMP SMP (Symmetric Multi Processing),对称多处理系统内有许多紧耦合多处理器,在这样的系统中,所有的CPU共享全部资源,如总线,内存和I/O系统等,操作系统或管理数据库的复本只有一个,这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。操作系统管理着一个队列,每个处理器依次处理队列中的进程。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。
所谓对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系。各 CPU 共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构 (UMA : Uniform Memory Access) 。对 SMP 服务器进行扩展的方式包括增加内存、使用更快的 CPU 、增加 CPU 、扩充 I/O( 槽口数与总线数 ) 以及添加更多的外部设备 ( 通常是磁盘存储 ) 。
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。
我们常用的计算机就是这种结构
NUMA 由于 SMP 在扩展能力上的限制,人们开始探究如何进行有效地扩展从而构建大型系统的技术, NUMA 就是这种努力下的结果之一。利用 NUMA 技术,可以把几十个 CPU( 甚至上百个 CPU) 组合在一个服务器内。
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。
利用 NUMA 技术,可以较好地解决原来 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。比较典型的 NUMA 服务器的例子包括 HP 的 Superdome 、 SUN15K 、 IBMp690 等。
但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。
代码中存在的问题说明
首先是在获取锁中锁重入的问题,其次是在释放锁中注释的两句代码的作用
CLHNode newCurNode = new CLHNode();
curNode.set(newCurNode);
重入问题
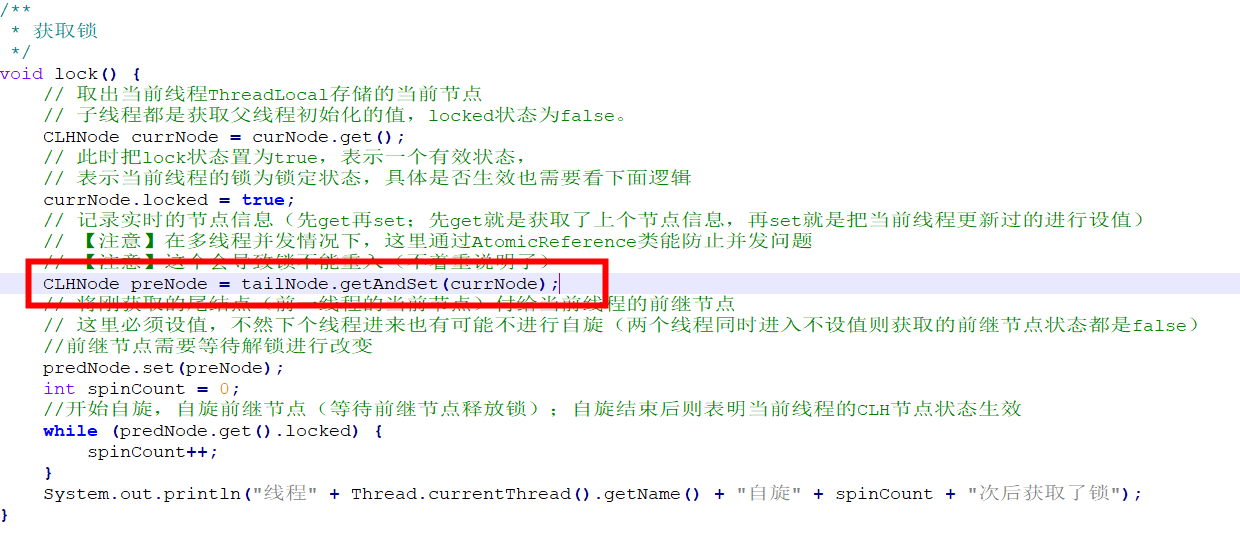 在截图代码中获取前继节点信息的时候,同时也会让tailNode节点引用引向最后一个队列。但是假设一个线程进行了重入,那么tailNode节点引用引向最后一个队列依旧是自己,但是所对象依旧在锁定状态,那么自旋就会一直进行下去。此时就会出现
在截图代码中获取前继节点信息的时候,同时也会让tailNode节点引用引向最后一个队列。但是假设一个线程进行了重入,那么tailNode节点引用引向最后一个队列依旧是自己,但是所对象依旧在锁定状态,那么自旋就会一直进行下去。此时就会出现死锁的问题。
解决方法:可以对应对节点信息加一个版本号(这个版本号统计记录在请求的线程中),同一个线程在进行重入的时候,如果版本号一直则不对前继节点进行更改(不做任何操作);这样就可以重入了。
public class CLHQueueLock {
/**
* CLH锁节点
*/
private class CLHNode {
AtomicReference<String> threadVersion = new AtomicReference<>();
/**
* 锁状态:true表示锁定状态、false表示释放状态
* 为了保证locked状态是线程间可见的,因此用volatile关键字修饰
*/
volatile boolean locked = false;
}
/**
* 当前节点
* 每个线程拥有自己的副本用于记录自己线程中持有的CLH节点状态信息
*/
private final ThreadLocal<CLHNode> curNode;
/**
* 前继节点(指向前一个线程中持有的CLH节点信息)
* 每个线程拥有自己的副本用于记录自己线程中持有的CLH节点状态信息
*/
private final ThreadLocal<CLHNode> predNode;
/**
* 最后一个队列种CLH节点的状态信息
* 【注意】这里用了java的原子系列之AtomicReference,能保证原子更新
*/
private final AtomicReference<CLHNode> tailNode;
/**
* 初始化几个节点信息
*/
CLHQueueLock() {
// 初始化当前线程(即实例化锁的线程)的CLH节点,锁状态为false;这个方法会为子线程创建副本
curNode = ThreadLocal.withInitial(CLHNode::new);
// 初始化前继节点,注意此时前,存储的是null
predNode = new ThreadLocal<>();
// 初始化最后一个队列种CLH节点的状态信息
tailNode = new AtomicReference<>(curNode.get());
}
/**
* 获取锁
*/
void lock() {
String currentThreadName = Thread.currentThread().getName();
// 取出当前线程ThreadLocal存储的当前节点
// 子线程都是获取父线程初始化的值,locked状态为false。
CLHNode currNode = curNode.get();
// 此时把lock状态置为true,表示一个有效状态,
// 表示当前线程的锁为锁定状态,具体是否生效也需要看下面逻辑
currNode.locked = true;
//判断是否重入,这里不是绝对安全,要想安全可以加锁
if (!currentThreadName.equals(currNode.threadVersion.get())) {
currNode.threadVersion.set(Thread.currentThread().getName());
// 记录实时的节点信息(先get再set;先get就是获取了上个节点信息,再set就是把当前线程更新过的进行设值)
// 【注意】在多线程并发情况下,这里通过AtomicReference类能防止并发问题
// 【注意】这个会导致锁不能重入(不着重说明了)
CLHNode preNode = tailNode.getAndSet(currNode);
// 将刚获取的尾结点(前一线程的当前节点)付给当前线程的前继节点
// 这里必须设值,不然下个线程进来也有可能不进行自旋(两个线程同时进入不设值则获取的前继节点状态都是false)
//前继节点需要等待解锁进行改变
predNode.set(preNode);
}
int spinCount = 0;
//开始自旋,自旋前继节点(等待前继节点释放锁);自旋结束后则表明当前线程的CLH节点状态生效
while (predNode.get().locked) {
spinCount++;
}
System.out.println("线程" + Thread.currentThread().getName() + "自旋" + spinCount + "次后获取了锁");
}
/**
* 释放锁
*/
void unLock() {
// 获取当前线程的当前节点
CLHNode node = curNode.get();
// 进行解锁操作
node.locked = false;
System.out.println("线程" + Thread.currentThread().getName() + "释放了锁!!!");
predNode.remove();
// 小伙伴们可以思考下,下面两句代码的作用是什么??
// CLHNode newCurNode = new CLHNode();
// curNode.set(newCurNode);
// 【优化】能提高GC效率和节省内存空间,请思考:这是为什么?
// curNode.set(predNode.get());
}
}
注释代码解释 这里先直接说结果:若没有这两句代码,若同个线程加锁释放锁后,然后再次执行加锁操作,这个线程就会陷入自旋等待的状态。
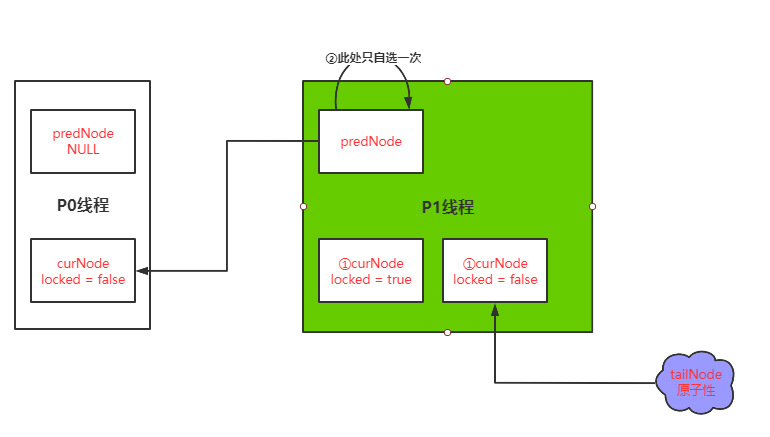
原因用图解释:
第一次线程P1先获取锁再释放锁
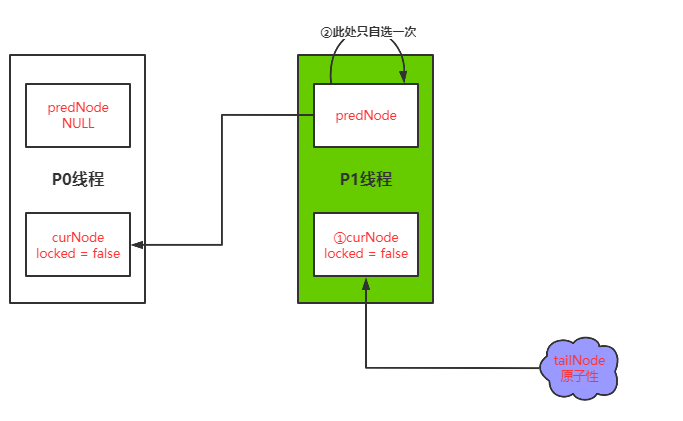
第二次线程P1再去获取锁,不会出现副本,所以再原有线程改变
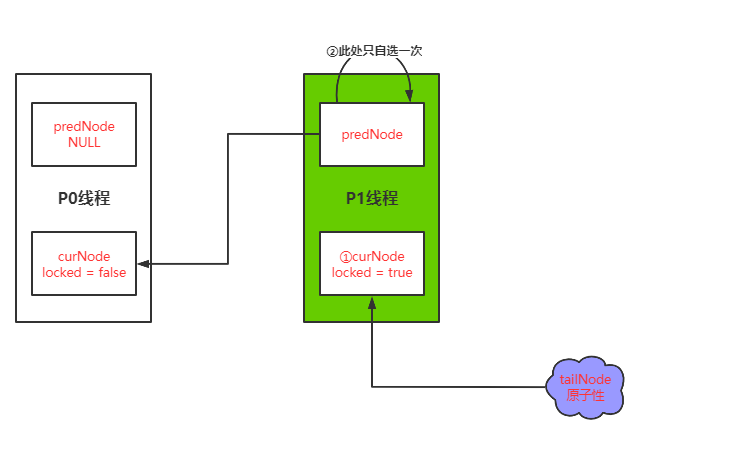 然后先获取taillNode的前继节点;此时前继节点如果P1两次获取不是同一个线程那么理论上视为前继节点已经为false状态;可是由于同一个线程所以获取的前继节点依旧是true;意思P1的前继节点predNode指向当前节点curNode;然而当前节点首先设值状态为true;所以此时就会进行自旋的死循环。
然后先获取taillNode的前继节点;此时前继节点如果P1两次获取不是同一个线程那么理论上视为前继节点已经为false状态;可是由于同一个线程所以获取的前继节点依旧是true;意思P1的前继节点predNode指向当前节点curNode;然而当前节点首先设值状态为true;所以此时就会进行自旋的死循环。
而这两行代码就是让tailNode指向新的地址,从而不影响前继节点实际状态的获取
最后实际应用多见于AQS,AQS可以理解为变种版、升级版的CLH;譬如在ReentrantLock中的应用


